CPU利用率:显示的是程序在运行期间实时占用的CPU百分比
CPU负载:显示的是一段时间内正在使用和等待使用CPU的平均任务数。CPU利用率高,并不意味着负载就一定大。举例来说:如果我有一个程序它需要一直使用CPU的运算功能,那么此时CPU的使用率可能达到100%,但是CPU的工作负载则是趋近于“1”,因为CPU仅负责一个工作嘛!如果同时执行这样的程序两个呢?CPU的使用率还是100%,但是工作负载则变成2了。所以也就是说,当CPU的工作负载越大,代表CPU必须要在不同的工作之间进行频繁的工作切换。
我们知道:
- 平均负载是指单位时间内,处在可执行状态和不可中断睡眠状态的进程的平均数。也就是说,它包括了处在执行态,阻塞态和就绪态的进程。
- CPU使用率是指在单位时间内CPU处于非空闲状态的时间比,反映了CPU的繁忙程度。例如:单核CPU单位时间内非空闲态运行时间为0.8s,那么他的CPU使用率为80%;双核CPU单位时间内非空闲态运行时间分别为0.4s和0.6s,那么它的CPU使用率为(0.4+0.6)/2*100%=50%
我们再举个更生动的例子: 有一家银行,他只有一个业务窗口,每次只能接待一个人(单核CPU)。有一天一共有五个人来了,那么就会出现一人在办理手续,其余四人在等待的情况(CPU负载为5) 我们约定在业务窗口的那个人只有真正在办理业务才算是真正使用(CPU使用率)如下图
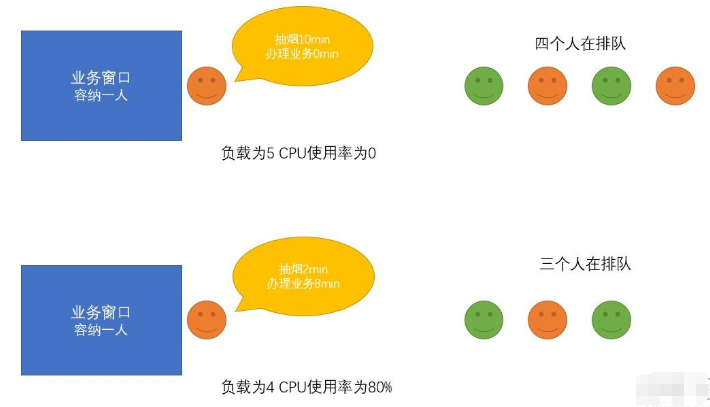
了解了负载与CPU使用率的关系之后,我们来聊聊什么情况下会导致负载上升以及平均负载和CPU使用率的关系
- CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
- I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
- 大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
Load分析:
情况1:CPU高、Load高
1.通过top命令查找占用CPU最高的进程PID;
2.通过top -Hp PID查找占用CPU最高的线程TID;
3.对于java程序,使用jstack打印线程堆栈信息(可联系业务进行排查定位);
4.通过printf %x tid打印出最消耗CPU线程的十六进制;
5.在堆栈信息中查看该线程的堆栈信息;
情况2:CPU低、Load高(此情况出现几率很大)
1.通过top命令查看CPU等待IO时间,即%wa;
2.通过iostat -d -x -m 1 10查看磁盘IO情况;(安装命令 yum install -y sysstat)
3.通过sar -n DEV 1 10查看网络IO情况;
4.通过如下命令查找占用IO的程序:
1 | ps -e -L h o state,cmd | awk '{if($1=="R"||$1=="D"){print $0}}' | sort | uniq -c | sort -k 1nr |
CPU高、Load高情况分析
使用 vmstat 查看系统纬度的 CPU 负载
可以通过 vmstat 从系统维度查看 CPU 资源的使用情况
格式:vmstat -n 1 表示结果一秒刷新一次
1 | [root@k8s-master01 ~]# vmstat -n 1 |
返回结果中的主要数据列说明:
1 | r: 表示系统中 等待处理的线程。由于 每次只能处理一个线程,所以,该数值越大,通常表示系统运行越慢。 |
使用 top 查看进程纬度的 CPU 负载
可以通过 top 从进程纬度来查看其 CPU、内存等资源的使用情况:
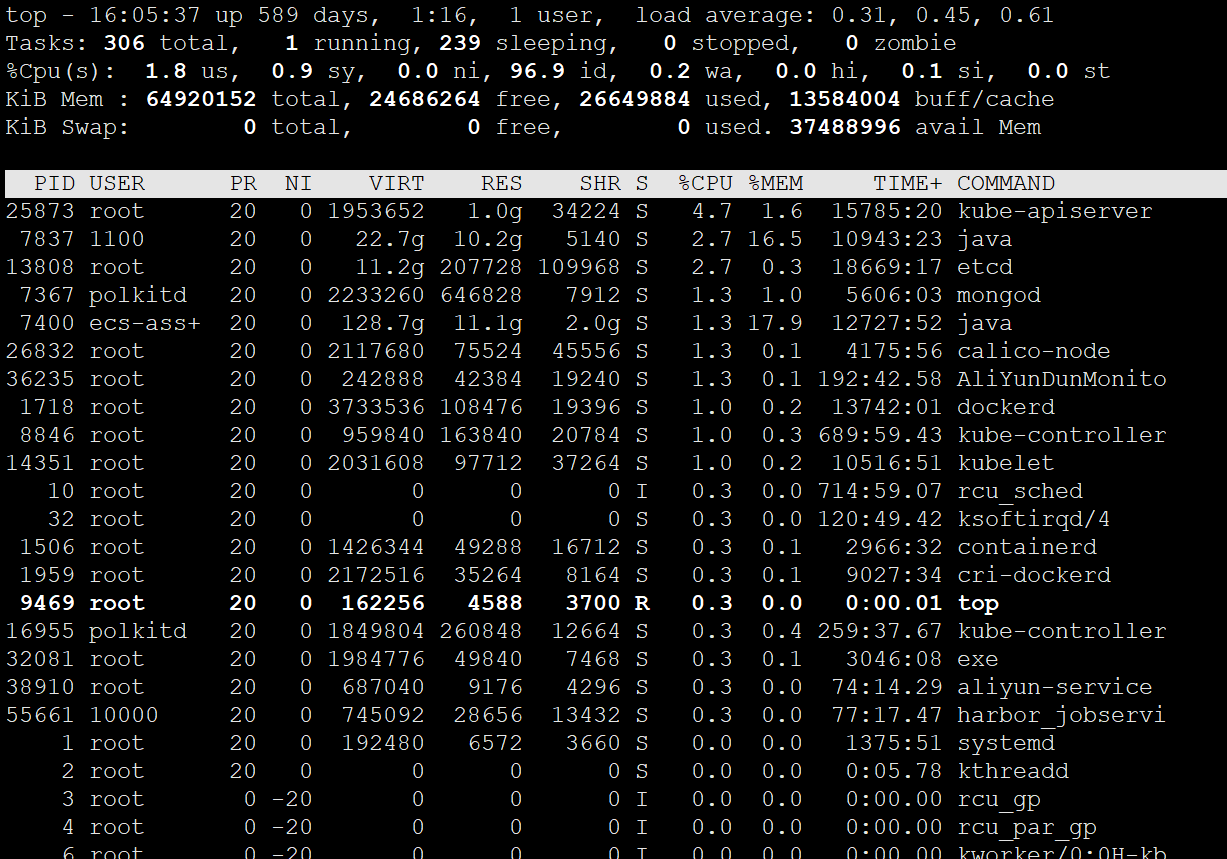
默认界面上第三行会显示当前 CPU 资源的总体使用情况,下方会显示各个进程的资源占用情况。
可以直接在界面输入大小字母 P,来使监控结果按 CPU 使用率倒序排列,进而定位系统中占用 CPU 较高的进程。最后,根据系统日志和程序自身相关日志,对相应进程做进一步排查分析,以判断其占用过高 CPU 的原因。
strace命令分析
1 | strace -tt -T -v -f -e trace=file -o /data/log/strace.log -s 1024 -p 23489 |
1 | -tt:在每行输出的前面,显示毫秒级别的时间 |
CPU低、Load高情况分析
问题描述:
Linux 系统没有业务程序运行,通过 top 观察,CPU 很空闲,但是 load average 却非常高。
处理办法:
load average 是对 CPU 负载的评估,其值越高,说明其任务队列越长,处于等待执行的任务越多。
出现此种情况时,可能是由于僵死进程导致的。可以通过指令ps -axjf查看是否存在 D 状态进程。
D 状态是指不可中断的睡眠状态。该状态的进程无法被 kill,也无法自行退出。只能通过恢复其依赖的资源或者重启系统来解决。
等待I/O的进程通过处于uninterruptible sleep或D状态,通过给出这些信息我们就可以简单的查找出处在wait状态的进程
1 | ps -eo state,pid,cmd | grep "^D"; echo "----" |
查找占用IO的程序:
1 | ps -e -L h o state,cmd | awk '{if($1=="R"||$1=="D"){print $0}}' | sort | uniq -c | sort -k 1nr |
案例分析
磁盘I/O, %util特别高
环境复现
- 环境配置:本次测试使用128C_512G_4TSSD服务器配置,MySQL版本为8.0.27
- 场景模拟:使用sysbench创建5个表,每个表2亿条数据,执行产生笛卡尔积查询的sql语句,产生io,可以模拟业务压力。
系统层面底层故障排查
1 | shell> sysbench --test=/usr/local/share/sysbench/oltp_insert.lua --mysql-host=XXX --mysql-port=3306 --mysql-user=pcms --mysql-password=abc123 --mysql-db=sysbench --percentile=99 --table-size=2000000000 --tables=5 --threads=1000 prepare |
使用sysbench进行模拟高并发
1 | shell> sysbench --test=/usr/local/share/sysbench/oltp_write_only.lua --mysql-host=xxx --mysql-port=3306 --mysql-user=pcms --mysql-password=abc123 --mysql-db=sysbench --percentile=99 --table-size=2000000000 --tables=5 --threads=1000 --max-time=60000 --report-interval=1 --threads=1000 --max-requests=0 --mysql-ignore-errors=all run |
执行笛卡尔积sql语句
1 | mysql> select SQL_NO_CACHE b.id,a.k from sbtest_a a left join sbtest_b b on a.id=b.id group by a.k order by b.c desc; |
检查当前服务器状态
1 | shell> top |
由上可知:目前一分钟负载为72.56,且呈上升趋势,并且存在io压力
查看当前各个磁盘设备的io情况
1 | shell> iostat -m -x 1 |
由上可知:目前有多块物理磁盘,sda磁盘的io压力较大
检查sda磁盘当前的io读写情况
1 | shell> iostat -d /dev/sda -m -x 1 |
由上可知:目前sda磁盘的压力比较大,每秒写入比每秒读差距较大,证明目前有大量的io写入
检查sda磁盘中哪个应用程序占用的io比较高
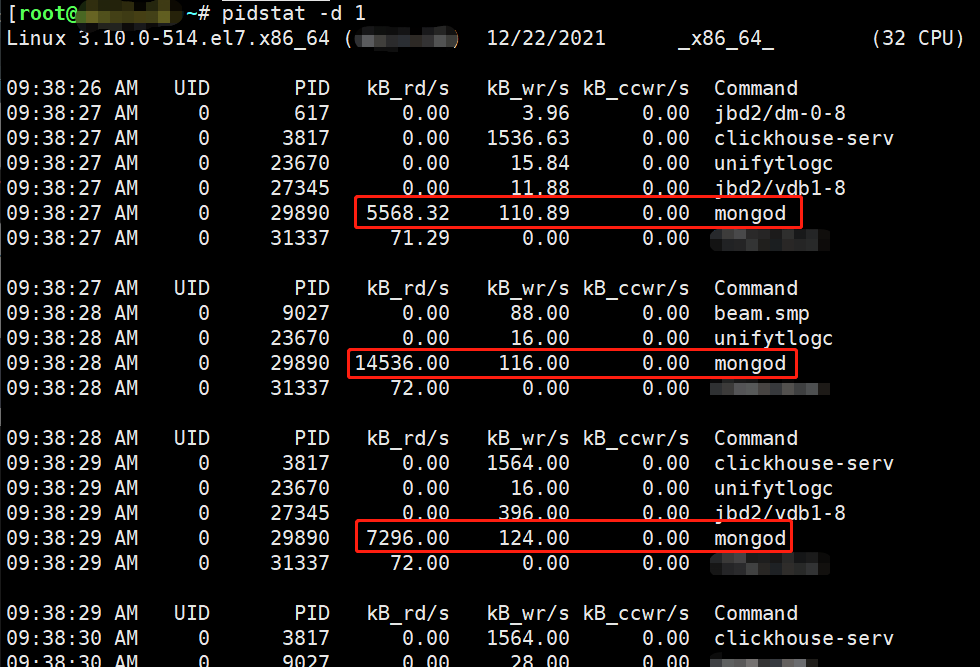
1 | shell> pidstat -d 1 |
由上可知:占用io高的应用程序是mysql,且pid为73739
分析应用程序中哪一个线程占用的io比较高
1 | shell> pidstat -dt -p 73739 1 执行两三秒即可 |
由上可知:74770这个线程占用的io比较高
分析这个线程在干什么?
1 | Shell> perf trace -t 74770 -o /tmp/tmp_aa.pstrace |
由上可知:目前这个线程在写入多个文件,fd为文件句柄,文件句柄号有64、159
查看这个文件句柄是什么
1 | shell> lsof -p 73739|grep 159u |
由上可知:这个线程在大量的写入临时文件
分析MySQL应用程序
查看当前的会话列表
1 | mysql> select * from information_schema.processlist where command !='sleep'; |
由上可知:目前这个sql已经执行了67s,且此sql使用了group by和order by,必然会产生io
通过线程号查询会话
1 | mysql> select * from threads where thread_os_id=74770\G; |
由上可知:通过查询threads表可以进行验证,该线程在频繁创建临时表的原因就来源于此sql
查看该sql语句的执行计划,进行进一步认证
1 | mysql> explain select SQL_NO_CACHE b.id,a.k from sbtest_a a left join sbtest_b b on a.id=b.id group by a.k order by b.c desc\G; |
由上可知:该sql的执行计划用到了临时表及临时文件,符合
查看全局状态进一步进行确认
1 | mysql> show global status like '%tmp%'; |
多执行几次,可以看出tmp_files和tmp_disk_tables的值在增长,证明在大量的创建临时文件及磁盘临时表,符合该线程的行为
故障处理
通过上述的一系列排查,我们已经分析出来:目前sda磁盘的io使用率最高,且mysqld程序占用的最多。
通过排查有一个线程在频繁的创建临时表或临时文件且通过登录mysql排查会话及线程视图可以找到是由某一个慢sql导致的。
查看此慢sql的执行计划也会创建临时表和临时文件符合我们之前排查的预期。
此时我们就需要针对此慢sql进行优化。
慢sql优化完成后可以进行io的继续观察,看io是否有下降。
代码分析
我们可以使用pstack进行跟踪线程号,获取当前的线程堆栈信息。切记pstack会调用gdb进行debug调试
1 | shell> pstack 74770 >/tmp/74770.pstack |
linux服务器磁盘IO持续飙高排查
问题发现
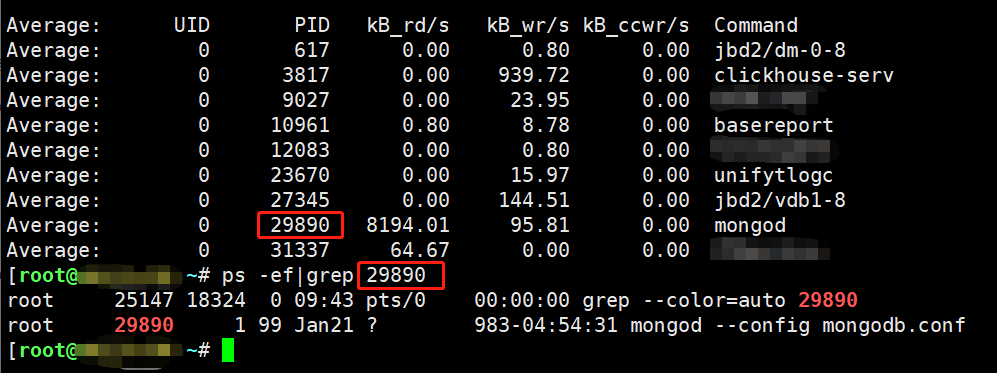
1 | 告警通知服务器的磁盘IO持续飙高,我们首先登录服务器,安装工具 |

1 | cpu属性值说明: |
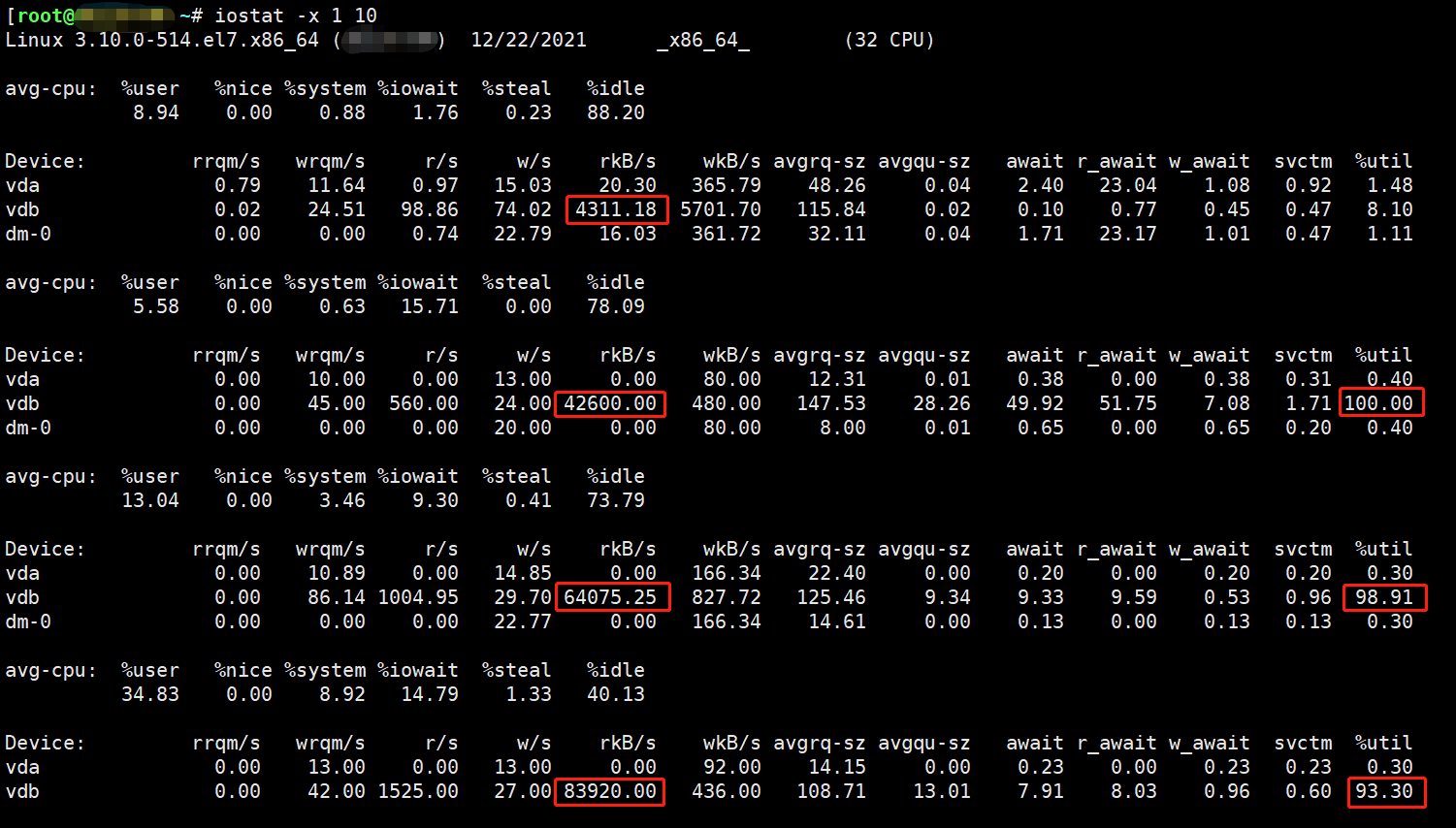
1 | 由上图可知,vdb磁盘的 %util【IO】几乎都在100%,原因是频繁的读取数据造成的 |
使用iotop命令找到IO占用高的进程
1 | iotop -oP展示I/O统计,每秒更新一次 |

pidstat 命令
1 | pidstat -d 1 检查哪个程序占用了IO |
服务器CPU使用率飙升
问题发现
告警群通知服务器CPU使用率高
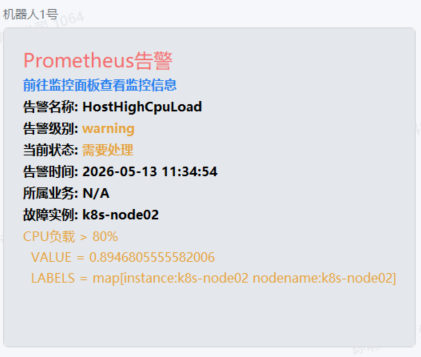
排查步骤
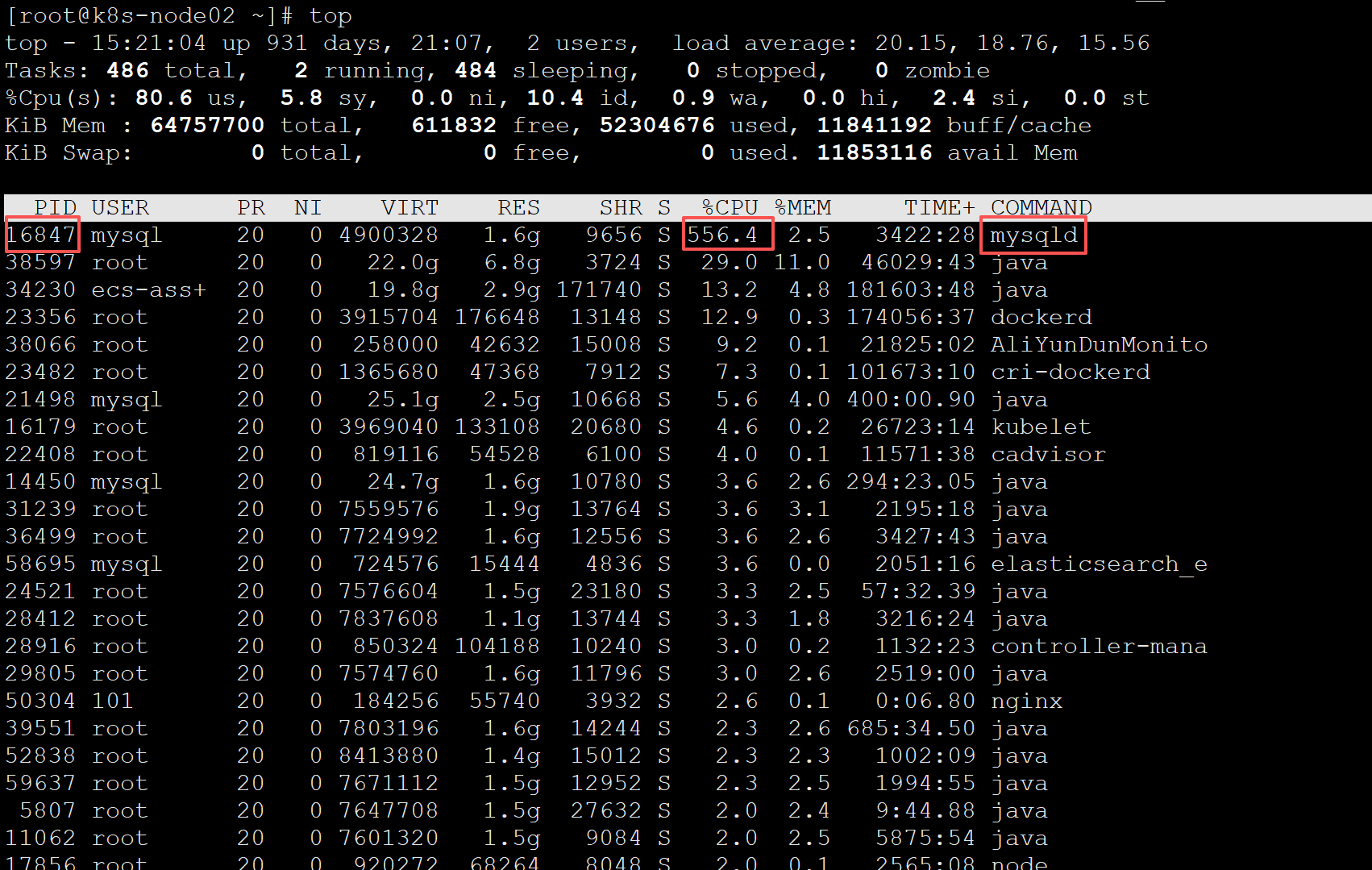
top命令查看
发现是mysql导致的CPU飙升,该进程的pid为16847
pidstat命令查看
1 | pidstat -t -p 16847 1 1 ##16847为mysql的pid |
查看%CPU列,看是哪个线程导致的
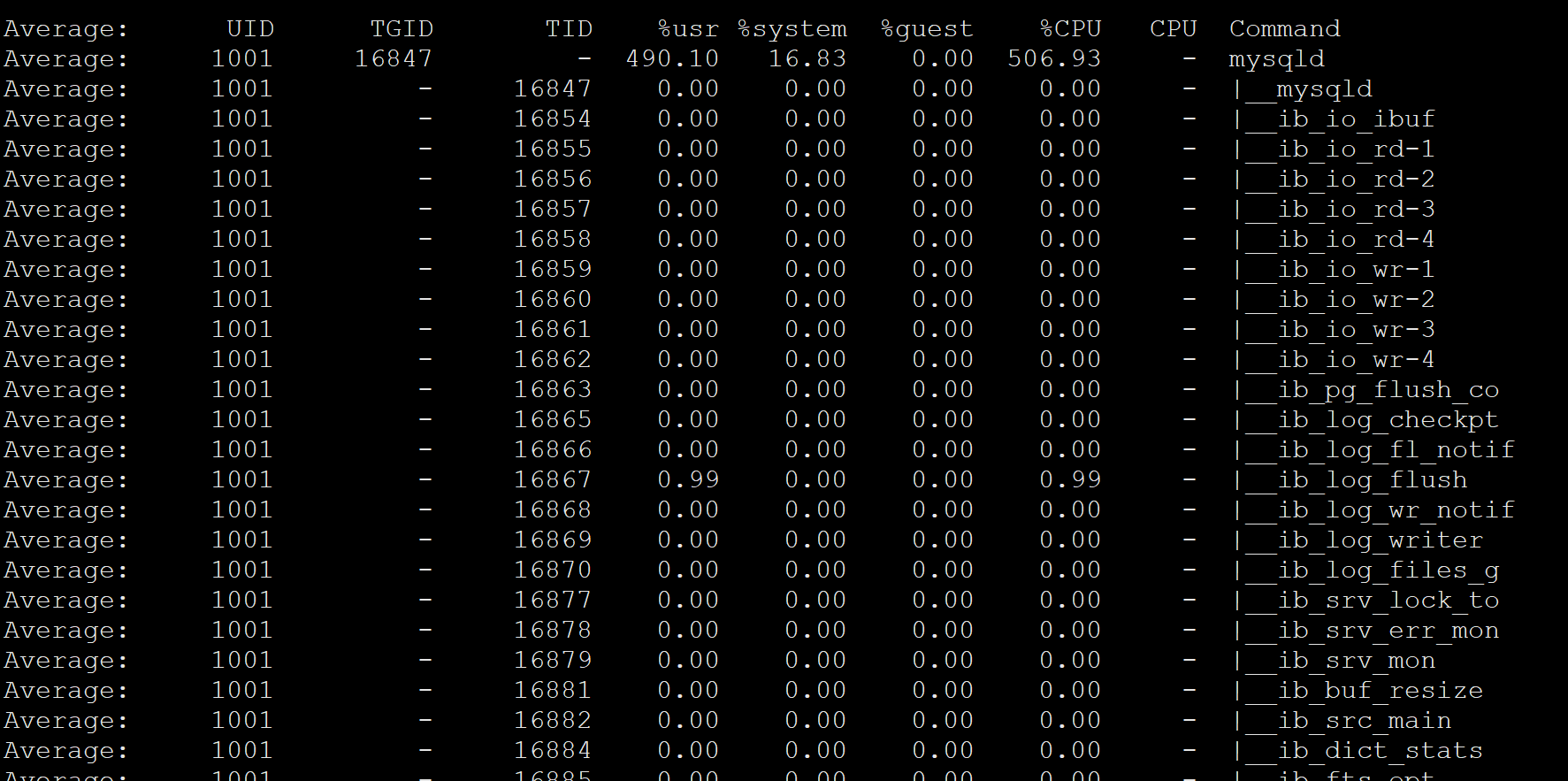
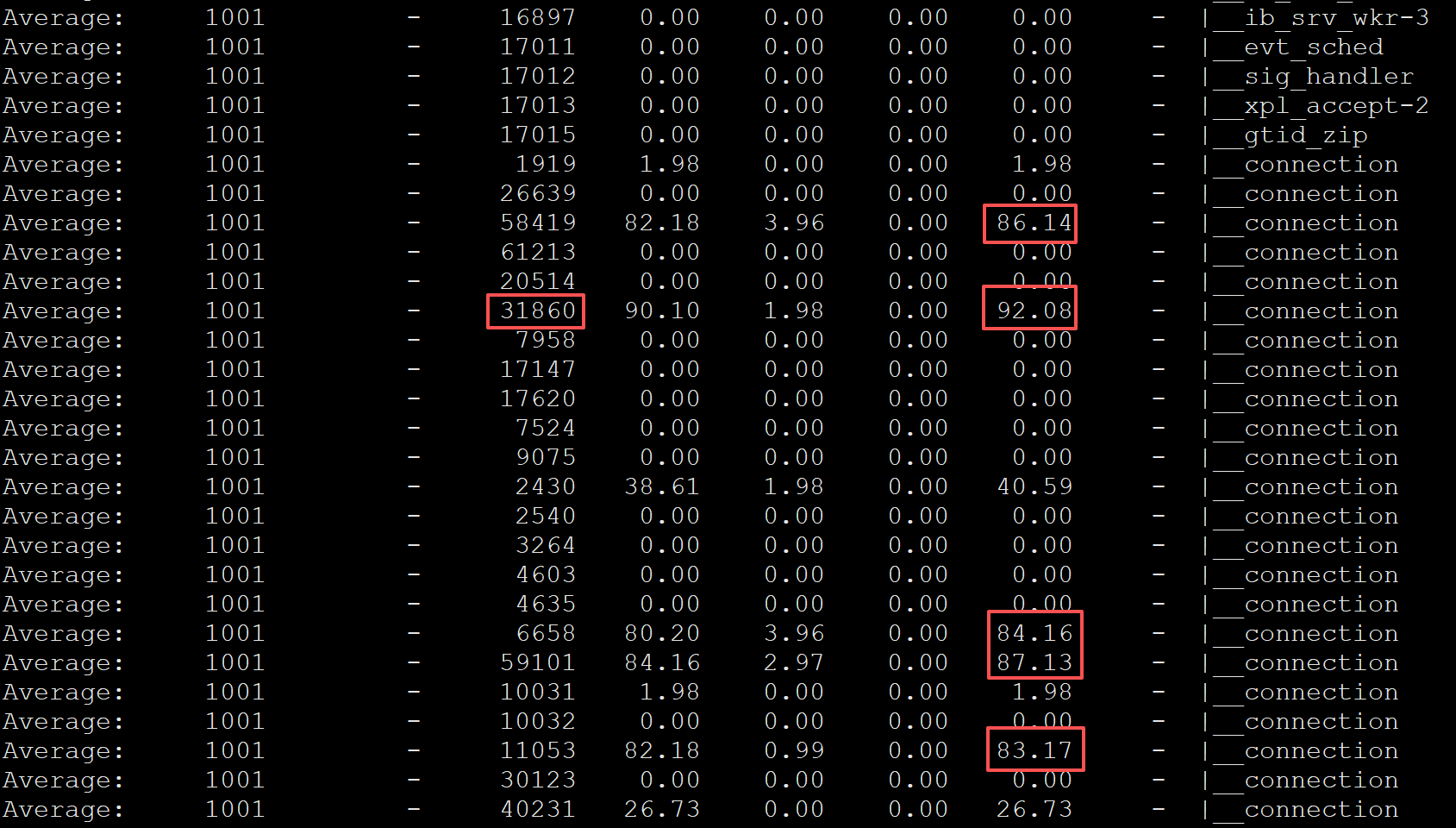
发现有好几个线程的CPU使用率都挺高,就用最高的线程来排查下,TID为31860
mysql查看
连接mysql执行以下命令看下这个线程具体的信息
1 | SELECT |
就可以看到这个线程的执行状态,时间,以及具体的sql等等信息,优化一下对应的sql就行。

