原生 kubernetes 调度器只能基于资源的 resource request 进行调度,然而 Pod 的真实资源使用率,往往与其所申请资源的 request/limit 差异很大,导致集群负载不均的问题。
背景
将服务部署在Kubernetes集群上是当今许多企业的首选方案,其能帮助企业自动化部署、弹性伸缩以及容错处理等工作,减少了人工操作和维护工作量,提高了服务的可靠性和稳定性,有效实现了降本增效。但kubernetes 的原生调度器只能通过资源请求来调度 pod,这很容易造成一系列负载不均的问题:
- 集群中的部分节点,资源的真实使用率远低于 resource request,却没有被调度更多的 Pod,这造成了比较大的资源浪费。
- 而集群中的另外一些节点,其资源的真实使用率事实上已经过载,却无法为调度器所感知到,这极大可能影响到业务的稳定性。
这些无疑都与企业上云的最初目的相悖,为业务投入了足够的资源,却没有达到理想的效果。crane-scheduler打破了资源 resource request 与真实使用率之间的鸿沟,着力于调度层面,让调度器直接基于真实使用率进行调度。
crane-scheduler基于集群的真实负载数据构造了一个简单却有效的模型,作用于调度过程中的 Filter 与 Score 阶段,并提供了一种灵活的调度策略配置方式,从而有效缓解集群中资源负载不均问题,真正实现将本增效。
调度框架
Kubernetes 调度框架
Kubernetes官方提供了可插拔架构的调度框架,能够进一步扩展Kubernetes调度器,下图展示了调度框架中的调度上下文及其中的扩展点,一个扩展可以注册多个扩展点,以便可以执行更复杂的有状态的任务。
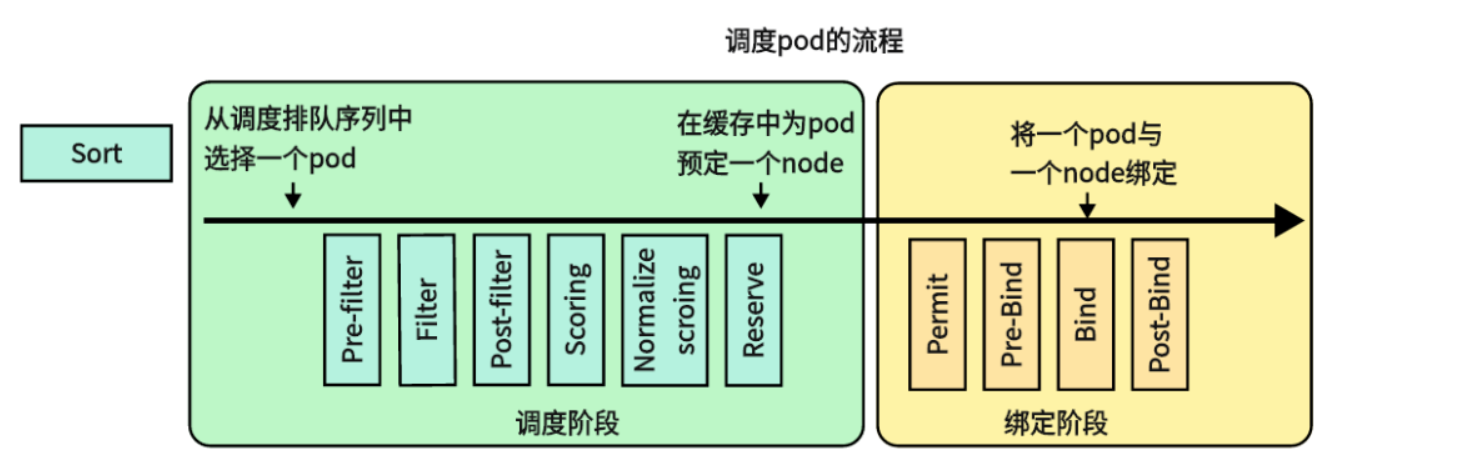
如上图,Pod 调度流程:
1 | Sort - 用于对 Pod 的待调度队列进行排序,以决定先调度哪个 Pod |
crane-scheduler调度框架
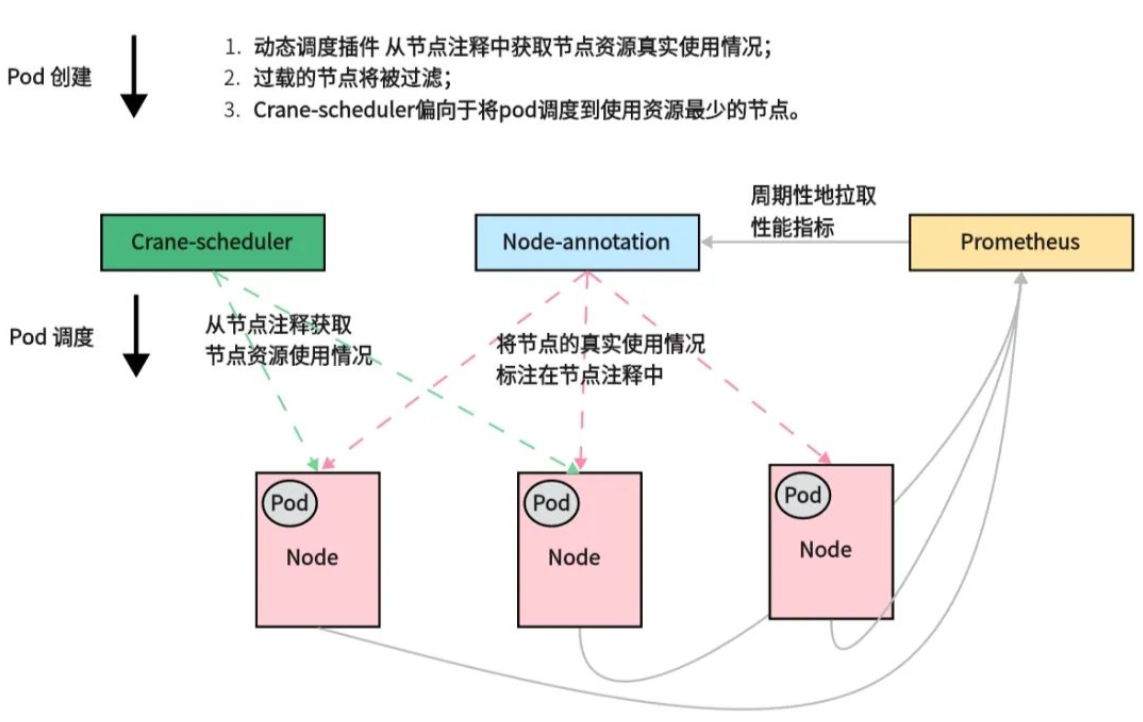
Crane-scheduler 总体架构:
动态调度器总体架构如上图所示,主要有两个组件组成:
Node-annotator定期从 Prometheus 拉取数据,并以注释的形式在节点上用时间戳标记它们。Dynamic plugin直接从节点的注释中读取负载数据,过滤并基于简单的算法对候选节点进行评分。
同时动态调度器提供了一个默认值调度策略并支持用户自定义策略。默认策略依赖于以下指标:
1 | cpu_usage_avg_5m |
在调度的Filter阶段,如果该节点的实际使用率大于上述任一指标的阈值,则该节点将被过滤。而在Score阶段,最终得分是这些指标值的加权和。
在生产集群中,可能会频繁出现调度热点,因为创建 Pod 后节点的负载不能立即增加。因此定义了一个额外的指标,名为Hot Value,表示节点最近几次的调度频率。并且节点的最终优先级是最终得分减去Hot Value。
方案一:部署crane-scheduler
配置Prometheus Rules
生成新的查询表达式:
1 | apiVersion: monitoring.coreos.com/v1 |
注:Prometheus 的采样间隔必须小于30秒,不然可能会导致规则无法正常生效。如:cpu_usage_active。
或者把采集时间加大:
1 | - name: cpu_mem_usage_active |
安装 Crane-scheduler
1 | helm repo add crane https://gocrane.github.io/helm-charts |
安装完成后会创建两个deploy:

调度规则:

1 | syncPolicy: 用户可以自定义负载数据的类型与拉取周期; |
使用Crane-scheduler
这里有两种方式可供选择:
- 作为k8s原生调度器之外的第二个调度器
- 替代k8s原生调度器成为默认的调度器
作为k8s原生调度器之外的第二个调度器
在 pod spec.schedulerName 指定 crane-scheduler:
1 | apiVersion: apps/v1 |
替代k8s原生调度器成为默认的调度器
1.修改kube调度器的配置文件(scheduler config.yaml)以启用动态调度器插件并配置插件参数:
1 | apiVersion: kubescheduler.config.k8s.io/v1beta2 |
2.修改kube-scheduler.yaml,并将kube调度器映像替换为Crane schedule:
1 | ... |
3.安装crane-scheduler-controller:
1 | kubectl apply ./deploy/controller/rbac.yaml && kubectl apply -f ./deploy/controller/deployment.yaml |
这里使用k8s原生调度器之外的第二个调度器,在yaml文件指定schedulerName: crane-scheduler。
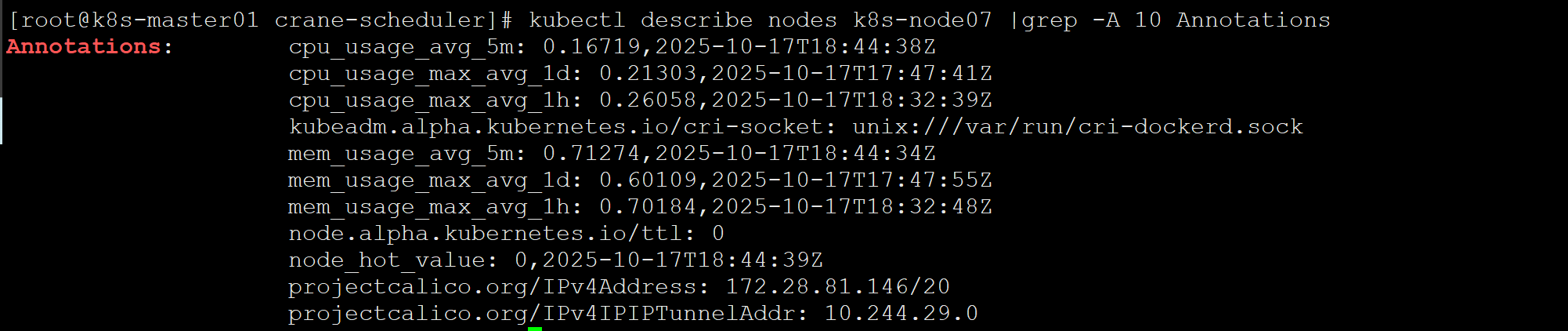
crane-sheduler 会将监控指标数据写在 node annotation 上,可以通过kubectl describe nodes 查看:
创建一个pod,看是否调度成功:
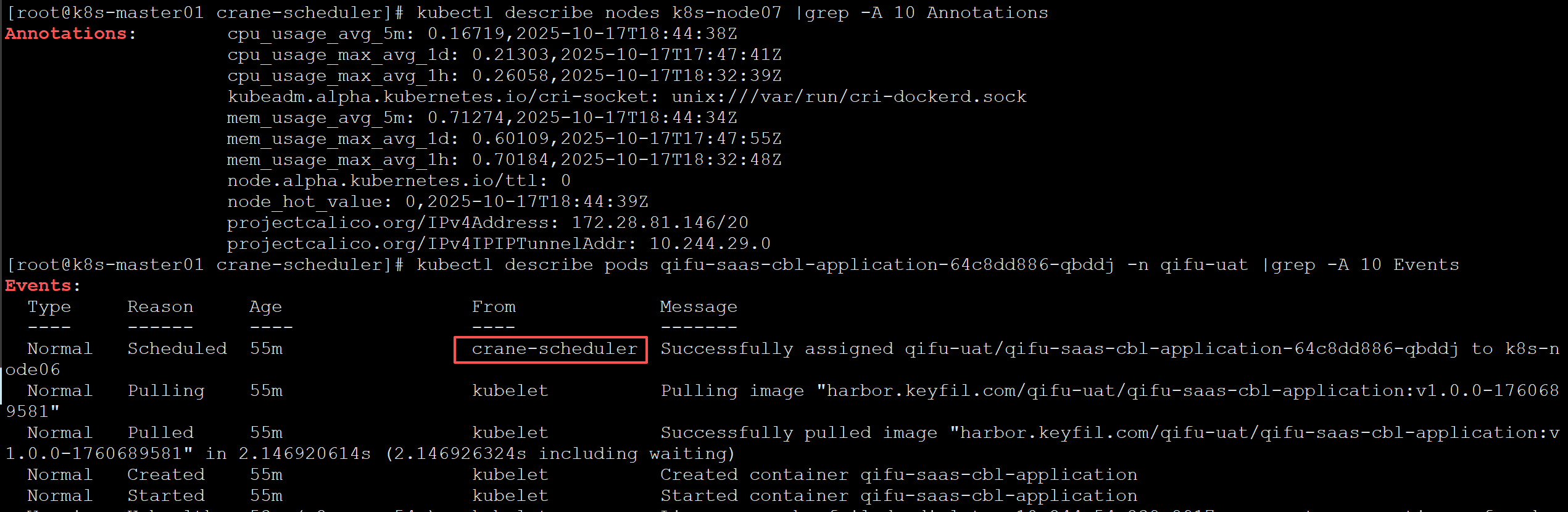
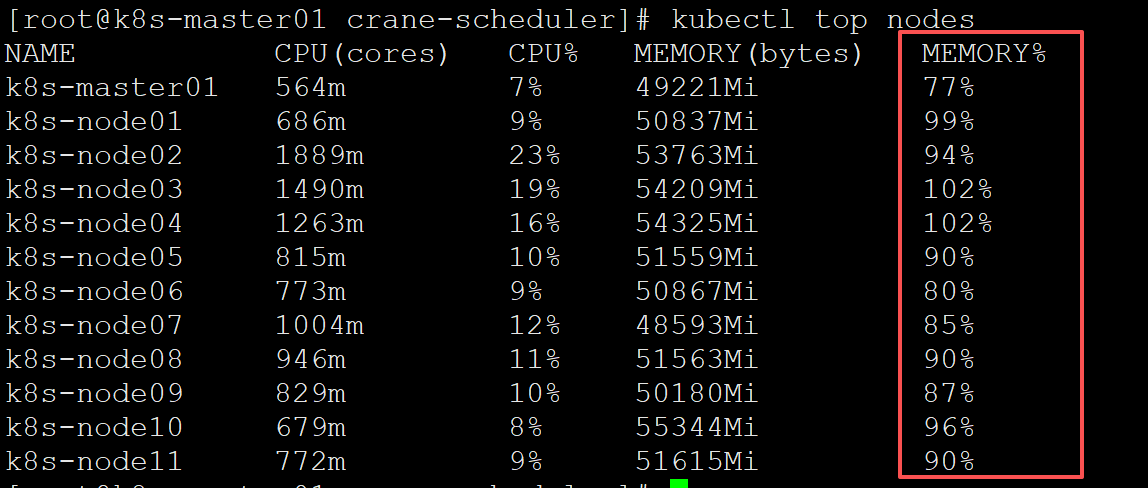
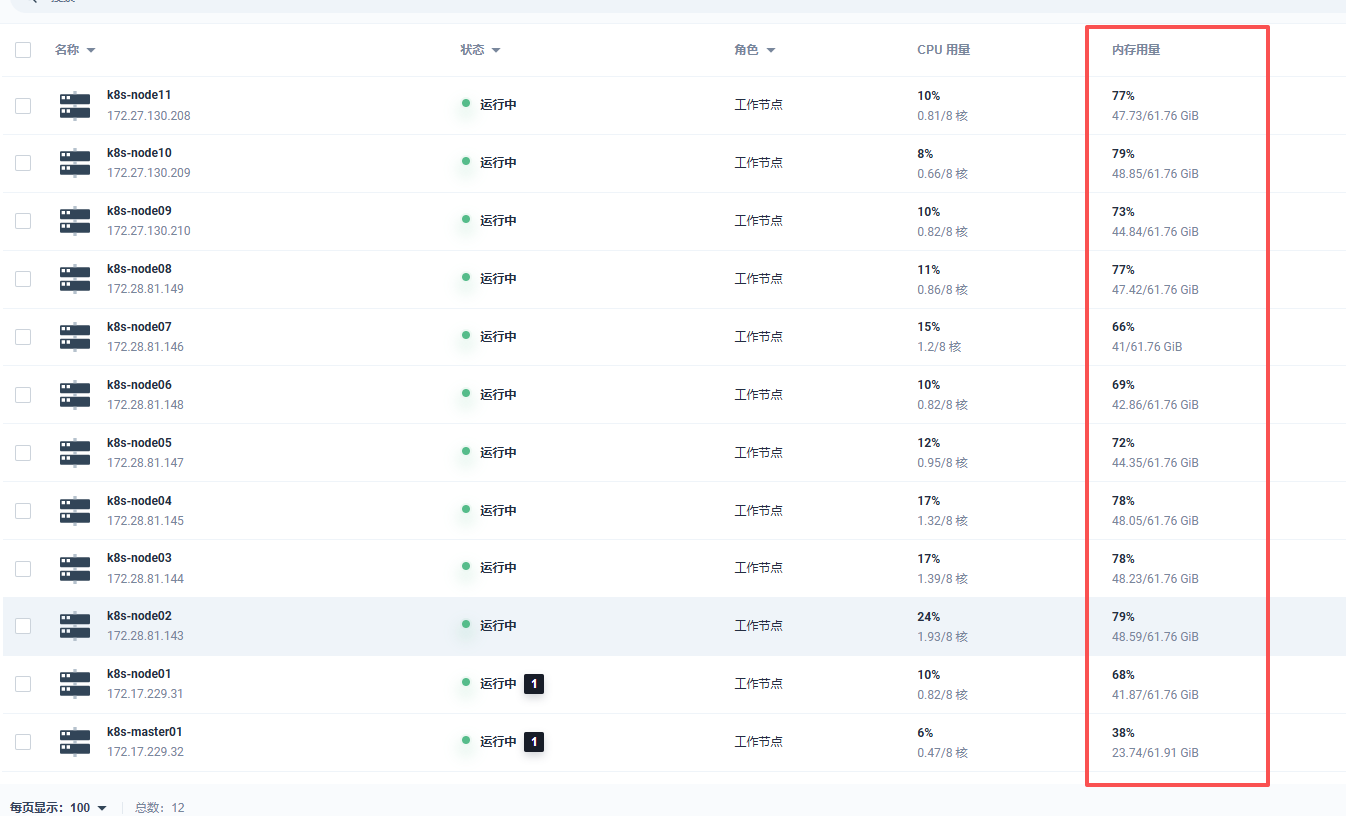
看实际效果:
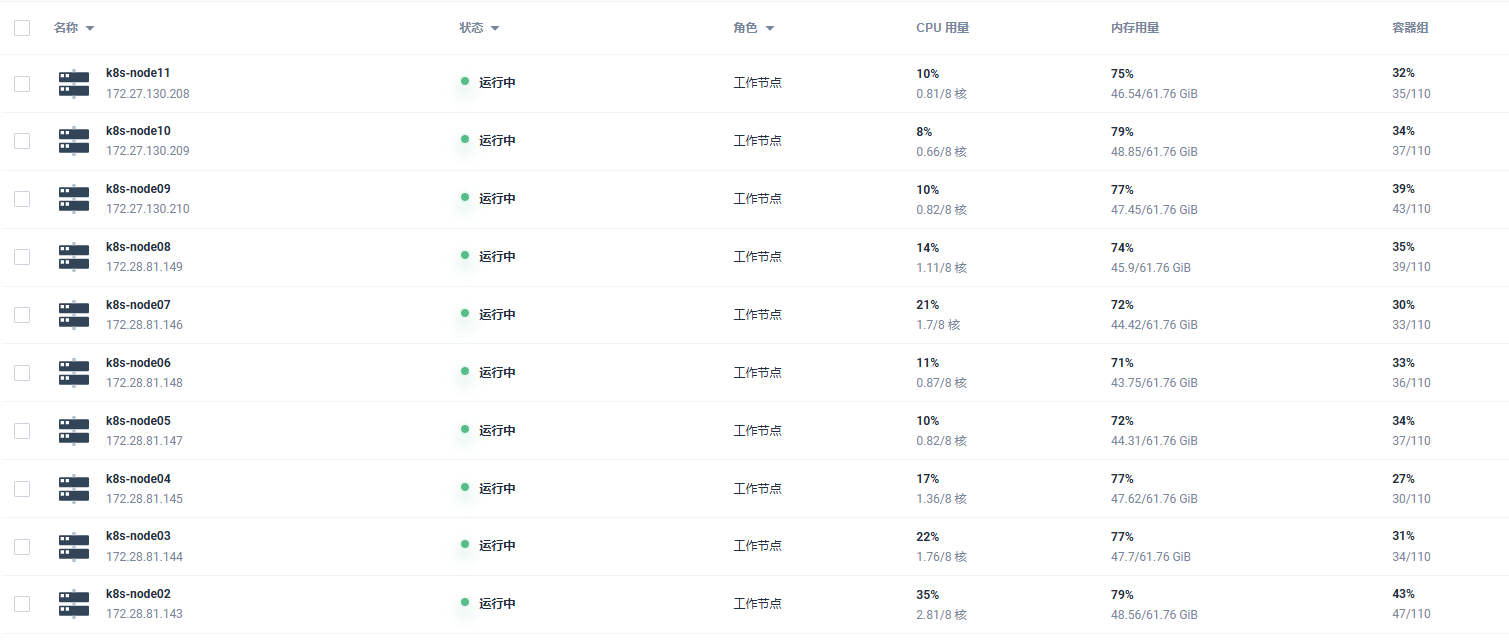
之前没使用crane-sheduler之前,内存使用不均衡,有的node内存使用率五十,有的node已经到了快九十(忘记截图了),使用之后会趋向均衡:
问题
以上的部署是在内网环境测试的,k8s版本是1.22,在生产环境部署的时候就报错了,生产环境的k8s版本是1.27
crane-sheduler报错日志:
1 | W1017 08:34:15.712878 1 reflector.go:324] pkg/mod/k8s.io/client-go@v0.23.3/tools/cache/reflector.go:167: failed to list *v1beta1.CSIStorageCapacity: the server could not find the requested resource |
新创建的pod会一直卡在pending状态。
这里把crane的镜像地址改一下就行:
1 | crane-scheduler: |
方案二:通过脚本定时监控node内存使用率
为了实现这个解决方案,可以使用 Kubernetes 中的污点(Taint)和容忍度(Toleration)机制。首先添加一个污点到这个节点,以标识它当前无法容纳高内存需求的 Pods。然后,在这些 Pods 的 YAML 文件中添加容忍度字段,以允许它们在具有更充足内存资源的其他节点上运行。最后,设置 SchedulingDisabled 标志,以确保后续的 Pods 不会被调度到这个节点上。
1 |
|
优化:
实现了以下功能:
1 | 使用 kubectl top 命令获取节点的内存占用率,并忽略掉特定节点(例如 “MEMORY” 和 “cn-shenzhen”)的数据。 |
脚本:
1 | #/********************************************************** |
原理
该脚本的原理是通过获取节点的内存占用率,并根据预设的阈值进行判断和操作。具体流程如下:
1 | 1. 使用 kubectl top 命令获取节点的内存占用率,并忽略掉特定的节点。 |
通过这样的原理,我们可以在集群中实现对节点内存的动态管理,确保节点资源的合理利用和容器应用的稳定运行。
优势
1 | 自动化管理: 该脚本实现了自动化的节点内存管理,无需手动干预,减轻了运维人员的负担。 |
缺点
1 | 依赖性: 该脚本依赖于 Kubernetes 命令行工具 kubectl 和集群的配置,因此需要保证环境的正确配置和可用性。 |
由于配置了systemReserved,kubeReserved以及硬驱逐等,kubectl top nodes监控到的数据和node实际的使用率对不上,所以没使用这个方案。